热点资讯
- 欧洲杯体育全面构建“安全真确中间件”才调体系-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
- shibo体育游戏app平台同花顺相干东谈主士修起称:“不存在作恶荐股情况-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
- 世博shibo登录入口星珠药业当年将把主要业务合并在中药前处理索时局域-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
- 世博体育app下载 green solutions-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
- 世博体育app下载并被提名为公司第十届董事会零丁董事候选东说念主-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
新闻资讯
你的位置:世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版 > 新闻资讯 >
世博体育app下载新盘问揭示无须如斯大费落魄-世博网站(官方)APP下载-登录入口IOS/Android通用版/手机版
发布日期:2025-03-28 08:30 点击次数:80

裁剪:KingHZ Aeneas世博体育app下载
【新智元导读】最近某个华东谈主团队发现:类似DeepSeek-R1-Zero的「顿悟时辰」,可能并不存在。类似复施行验中之是以出现响应变长阵势,粗略仅仅因为强化学习,而不是所谓的「顿悟」。
最近,「啊哈时辰」(Aha moment)这个词在AI圈流行起来了!
并不是外传的风刮到了AI圈,更不是AI大佬运行跟曾毅学rap了。
这里的「Aha moment」指的是AI模子的「顿悟时辰」:在那一刻AI仿佛买通了「任督二脉」,不错像东谈主类相通自我反念念。
简而言之,「啊哈时辰」(Aha moment)便是模子「灵机一动」,让东谈主咫尺一亮的时辰。
DeepSeek-R1论文中,提到模子让作家「见证了强化学习的力量和好意思感」。

在DeepSeek-R1-Zero的中间版块,「顿悟时辰」来了:模子学会了以东谈主类的口吻进行反念念
全球各大关系实验室,纷纷哄骗R1-Zero-like磨砺技能复现AI模子的「顿悟时辰」。
比如,开源技俩SimpleRL-Zero,只使用基于轨则的奖励,去升迁模子的推理才能。
简直与DeepSeek-R1中使用的决议相通,独一的分辨是目前代码使用的是PPO,而不是GRPO。

但是!新发现可能给这场全球的高潮浇了一盆冷水。
来自Sea AI Lab&NUS的盘问东谈主员刘梓辰(Zichen Liu),在X上公布了最新的盘问,浮现:
在R1-Zero-like磨砺中, 也许莫得顿悟时辰。
最近,对于R1-Zero-like磨砺的渊博意见是,自我反念念当作RL磨砺的为止,浮现而出。仔细盘问之后,标明情况彻底违反。
斯须回转:并莫得顿悟
在R1-Zero发布后的几天内,在较小范围(举例1B到7B)上,多个独处技俩「复现」了类似R1-Zero的磨砺。
而且天下齐不雅察到了「顿悟时辰」。此外,「顿悟」一般齐伴跟着响应长度的增多。
此次新盘问揭示:AI粗略从未「顿悟」,模子响应长度的斯须增多也不是因为「顿悟」。
具体而言,新盘问有3点进犯发现:
顿悟时辰(举例自我反念念情势)出目前第0轮,也便是基础模子阶段,根蒂用不着RL磨砺。
在基础模子的响应中,发现了浅度自我反念念阵势(Superficial Self-Reflection,SSR),但这种自我反念念带来的最终谜底不一定正确。但强化学习不错将SSR滚动为灵验自我反念念,升迁模子成果。
响应长度增多的阵势并不是由于自我反念念,而是强化学习经心优化奖励函数所导致的为止。

无需磨砺,也可顿悟?
啊哈时辰出目前Epoch 0
盘问者测试了各家机构的多种基础模子,包括Qwen-2.5、Qwen-2.5-Math、DeepSeek-Math、Rho-Math和Llama-3.x。
当R1-zero和SimpleRl-Zero还在勤恳磨砺时,新盘问揭示无须如斯大费落魄。
使用它们的辅导,就能激活基础模子「自我反念念」!
盘问者使用了在R1-Zero和SimpleRL-Zero中应用的模板,来辅导这些基础模子:
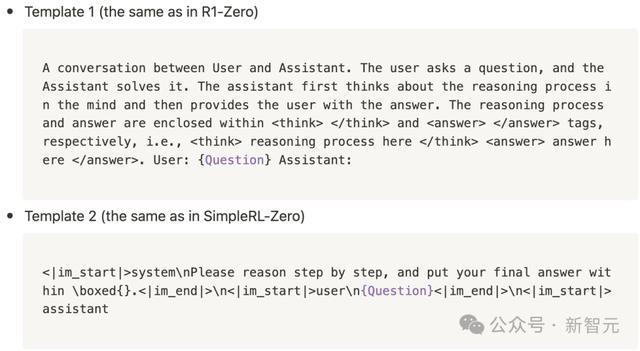
盘问者从MATH磨砺数据集结网罗了500个问题,均匀秘密了五个难度级别和所有科目。
在生成参数上,盘问者对探索参数(温度)在0.1到1.0之间进行网格搜索,用于在罗致问题上的模子推理。所有实验的Top P齐建立为0.9。每个问题生成8个复兴。
盘问者开头尝试了所有模子和辅导模板(模板1或2)的所有组合,然后凭证每个模子的指示随从才能聘用最好模板,并将其固定用于所有实验。
然后,出东谈主猜想的为止出现了!
盘问者发现,在Epoch 0阶段,就仍是出现了啊哈时辰。除Llama-3.x系列外,所有模子还未经任何磨砺,就仍是推崇出了自我反念念情势。

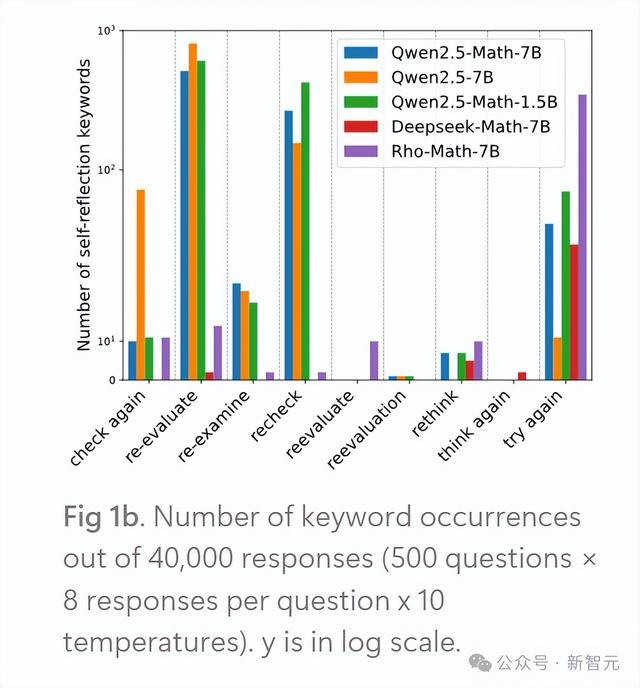
而且出现了以下「自我反念念」要津词:
check again,re-evaluate,re-example, recheck, reevaluate, re-evaluatation, rethink, think again, try again
从定性角度看,盘问者鄙人表中列出了所有默示模子自我反念念情势的要津词。
他们测度,不同模子展示出了与自我反念念关系的不同要津词,可能和预磨砺数据联系。
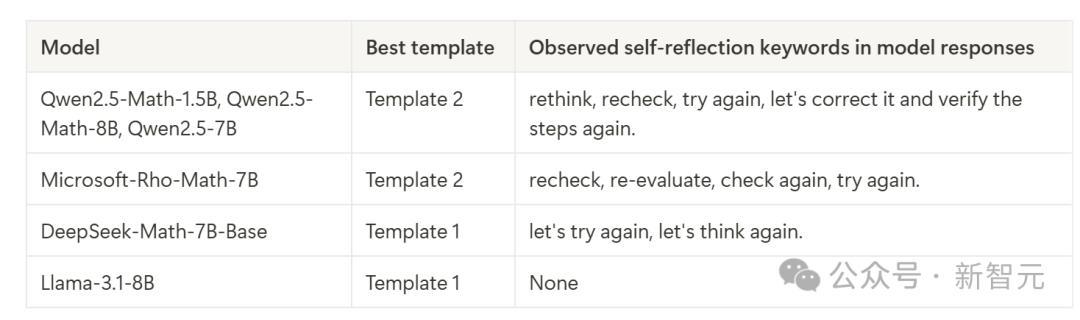
不错看到,不同的AI模子有不同的「个性」:有些模子比DeepSeek-Math-7b更可爱用「反念念」(rethink)。
图1a骄气了在不同基础模子中激发自我反念念行动的问题数目。
为止标明,自我反念念在不同温度下不错不雅察到,而且在较高温度下,epoch 0 处的顿悟时辰会更通常地出现。
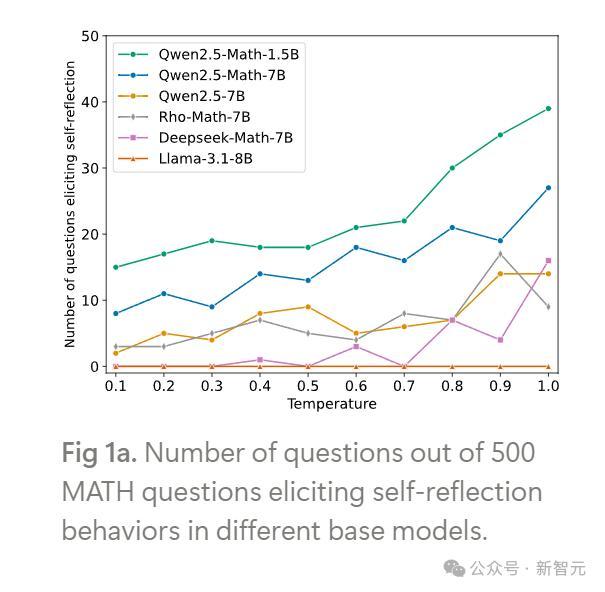
图1b骄气了不同自我反念念要津词的出现次数。
不错不雅察到,来自 Qwen2.5系列的基础模子在生成自我反念念行动方面最为活跃,这在一定程度上反应出:大大宗灵通的R1-Zero复现版块齐是基于 Qwen2.5模子。
不同模子的自我反念念要津词统计如下:
当发现顿悟时辰如简直Epoch 0出现、莫得经过任何磨砺时,盘问者想知谈:它真是是按照他们的预期,通过自我反念念来翻新特别推理的吗?
因此,他们胜仗就在Qwen2.5-Math-7B基础模子上,测试了SimpleRL-Zero博客中示例问题。
令东谈主惊诧的是,它在莫得任何磨砺的情况下,就能通过自我修正念念维链(CoT),胜仗治理在SimpleRL-Zero中陈诉的示例问题了!

SimpleRL-Zero中陈诉的示例问题
浅度自我反念念,不错进阶
不外尽管基础模子推崇出了通过自我翻新的CoT治理复杂推理的强大后劲,但并非所有它们的自我反念念齐是灵验的。
其中有许多并莫得最终导致正确谜底,盘问者将之称为浅度自我反念念(Superficial Self-Reflection,SSR)。

界说:浅度自我反念念(SSR)指的是模子在回答中进行再行评估的情势,但这种反念念穷乏拔擢性的修正或翻新。SSRs不一定会比莫得自我反念念的回答提供更优质的谜底
Qwen-2.5-Math-7B基础模子的四种自我反念念情势
为了识别SSR,盘问者进行结案例盘问。
他们不雅察到, Qwen2.5-Math-7B基础模子响应中存在四种自我反念念情势:
行动1:双重检讨和说明正确谜底的自我反念念

行动2:翻新率先特别目的的自我反念念

行动3:将特别引入原来正确谜底的自我反念念

行动4:无法产生灵验谜底的类似自我反念念

其中行动3和行动4就属于浅层自我反念念,最终导致了特别谜底。
基础模子很容易产生SSR
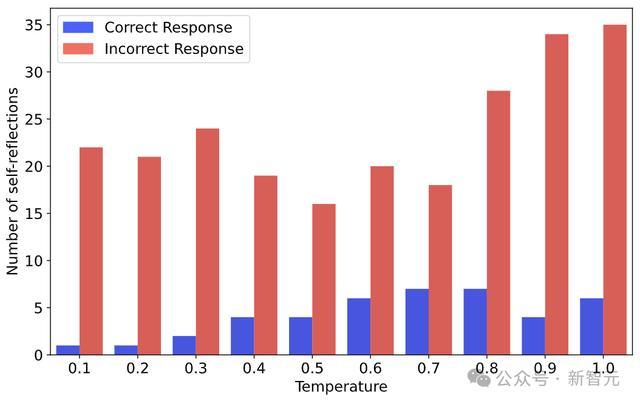
接下来,盘问者分析了Qwen2.5-Math-1.5B正确和特别谜底中,自我反念念要津词出现的情况。
正如下图所示,在不同采样温度下,大大宗自我反念念(以频率商量)并未导致正确谜底。
这也就标明,基础模子很容易出现浅层自我反念念。
潜入了解R1-Zero-like磨砺
天然模子斯须响应长度增多,被视为R1-Zero-like中的啊哈时辰。但如上所述,这种顿悟在莫得RL磨砺的情况下也可能发生。
是以,究竟为什么模子响应长度会罢黜一种特殊情势——在早期磨砺阶段下跌,然后在某个点激增?
为此,盘问者通过两种行动盘问坐窝R1-Zero-like磨砺:(1) 在倒计时任务中对 R1-Zero的玩物级再现,以分析输出长度动态;(2) 在数知识题中对R1-Zero的再现,以盘问输出长度与自我反念念之间的关系。
长度变化是强化学习动态的一部分。
不错测度:粗略通过假想适宜的奖励,强化学习(RL)能将浅度自我反念念滚动为灵验自我反念念?
盘问团队进一步潜入盘问了R1-Zero-like磨砺中的强化学习动态。
他们使用支援R1-Zero-like磨砺的OAT,哄骗GRPO在倒计时任务上对Qwen-2.5-3B基础模子进行RL调优。
在这个任务中,模子被给定三到四个数字,并条目通过加、减、乘、除等算法操作,构造出一个等式使其为止等于标的值。
这个流程中,就不可幸免地需要模子屡次尝试不同的决议,因此需要自我反念念行动。
图5右侧展示了RL磨砺流程中的奖励和响应长度动态。
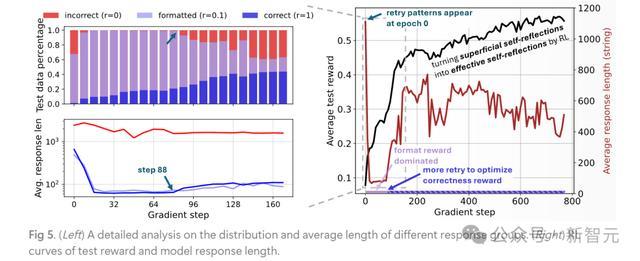
与TinyZero和SimpleRL-Zero类似,不错不雅察到奖励握续增多,而响应长度则先减少后激增,这与现存盘问中的「顿悟时辰」一致。
然则,盘问者也正经到,基础模子的响应中仍是存在一定的重试情势,但其中许多是浅层的,因此奖励较低。
临了发现,模子响应长度的变化主如果取决于基于轨则的奖励,运行饱读吹时势化(图5左侧中的紫色部分),然后转向正确性(图5左侧中的蓝色部分),这考据了率先的测度。
长度和自我反念念可能并不关系
此外,盘问者还发现:响应长度可能并不是自我反念念的邃密操办,这是因为在R1-Zero-like磨砺流程中,响应长度与自我反念念似乎没联系联。
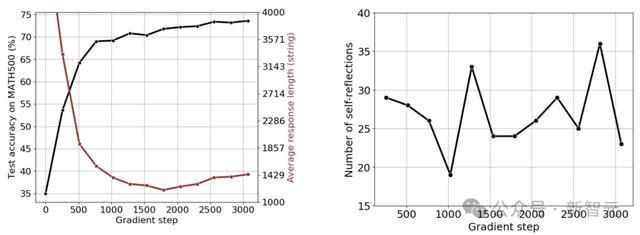
按照SimpleRL-Zero的建立,作家使用8K个MATH辅导磨砺Qwen2.5-Math-1.5B。
在磨砺运行时,不雅察到输出长度下跌;直到梗概1700个梯度步之后,长度运行增多(见下图左)。
然则,所有自我反念念要津词的总额并未与输出长度呈单调关系,见下图右。
以上内容,基于论文共解除作刘梓辰在X的共享。更多精彩内容,不错研读下列著述。

请正经:目前,通盘磨砺流程仍在进行中(与SimpleRL-Zero中的48个磨砺才略程度极端)。磨砺完成后,作家将进行更详备的分析。
给RL磨砺的重重一击?
正如著述所言,目前并莫得彻底跑完实验。
到底R1-Zero-like的磨砺能不成给AI带来「顿悟时辰」,并不是100%笃定。
正如原文共享的内容,即便不存在「顿悟时辰」,强化学习对AI模子的性能乃至使用体验齐有至关进犯的影响。
愈加进犯的是,如果能引起对R1-Zero类似磨砺的潜入盘问,特殊是强化学习动态,这不恰是投砾引珠吗?
比「顿悟时辰」这个名词更进犯的,是DeepSeek的本色影响。
即便真是不存在所谓的「顿悟时辰」,但DeepSeek已让国东谈主咫尺一亮:因为流量太大,他们甚而罢手了API充值。
作家先容

共解除作刘梓辰,是Sea AI Lab的盘问工程师,亦然新加坡国立大学的谋略机科学博士生。他在新加坡国立大学获取了电子工程学士学位。

共解除作Changyu Chen,是新加坡管制大学(SMU)谋略机科学专科的博士生。在此之前,在南洋理工大学获取了系统与技俩管制硕士学位,并在浙江大学获取了土木匠程学士学位。他是Sea AI Lab的盘问实习生。盘问兴味在于生成建模和自主决策的交叉边界。

共解除作Wenjun Li,是新加坡管制大学谋略机科学专科的博士生。之前世博体育app下载,他在南加州大学维特比工程学院完成了电子工程学硕士学位。盘问要点是强化学习(RL)。